
Learn how to organize, rank, and manipulate tabular data in Python using pandas with hands-on examples from real engineering datasets.
Introduction
If you’ve ever worked with messy spreadsheets, lab reports, or machine-generated logs, you’ve likely needed to sort, rank, or clean duplicate entries. In data science and engineering, organizing your data before analysis is just as important as the analysis itself.
This blog walks you through practical pandas operations—sorting, ranking, indexing, and handling duplicate labels—using two real-world datasets:
material.csv– a detailed dataset of engineering materials and their mechanical properties.Data.csv– another materials dataset used to reinforce concepts around index manipulation.
You can find the full notebook and datasets here on GitHub.
Why This Topic Matters
- Sorting helps prioritize important rows (e.g., strongest materials).
- Ranking is vital for comparisons, competitions, or evaluations.
- Indexes let you control row labels—especially useful when tracking duplicates or working with time-series data.
locandilocprovide flexible ways to access or modify your data based on labels or positions.
For engineers and AI practitioners, these are foundational skills in both data preprocessing and feature engineering workflows.
What’s Inside the Notebook?
Let’s break down the key sections covered:
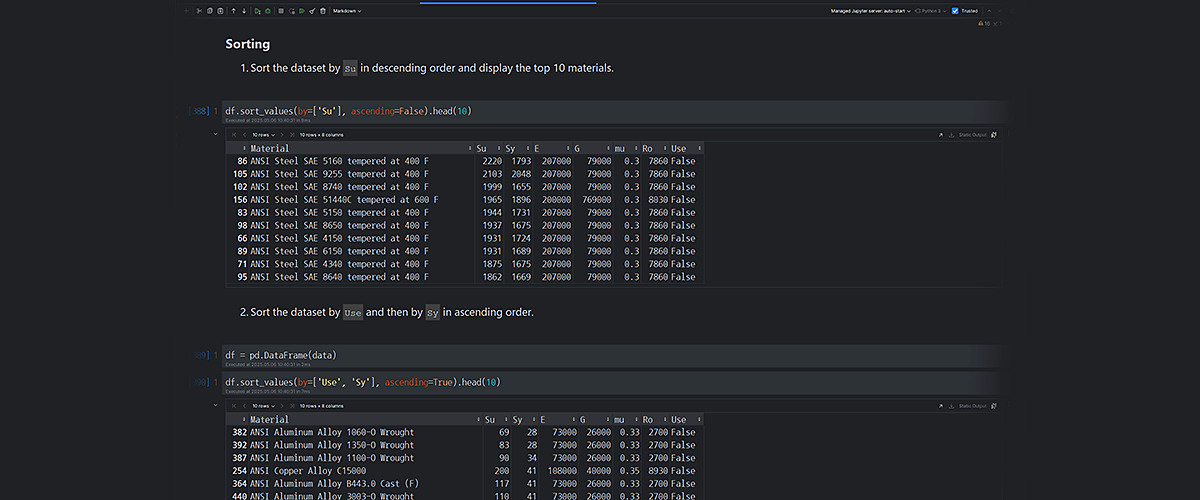
1. Sorting
- Sort materials by strength (
Su) to find the top performers. - Handle sorting with
NaNvalues. - Sort by multiple columns or by index itself.
2. Ranking
- Rank materials using methods like
'average','min','dense', and'first'. - Combine multiple property ranks (
Su,Sy,E) into a single composite rank. - Visualize rank logic to support material selection and grading.
3. Duplicate Indexes
- Duplicate rows intentionally to simulate real-world messiness.
- Check for non-unique index values using
.index.is_unique. - Use
duplicated()withkeep=Falseto find all repeated records.
4. loc and iloc Practice
- Use
locto select materials with specific property conditions. - Use
ilocfor positional slicing, updates, and reversals. - Replace specific values conditionally—ideal for cleaning or modifying experimental data.
Engineering & AI Use Cases
Here’s how these pandas techniques can be applied in real-world scenarios:
| Field | Application |
|---|---|
| Mechanical Engineering | Material property filtering and selection |
| Manufacturing | Eliminate duplicate sensor readings or machine logs |
| AI & Machine Learning | Feature ranking and dataset normalization |
| Data Science | Preprocessing datasets for clean and valid analysis |
These skills are essential when working with sensor data, simulations, SCADA systems, or historical test results.
Sample Problem: Find Top 5 Strongest Materials
df['Strength_Rank'] = df['Su'].rank(ascending=False, method='min').astype(int)
df.sort_values(by='Strength_Rank').head(5)
This snippet helps you quickly identify the top-performing materials based on tensile strength (Su). Ideal when creating material recommendation systems!
Tips to Remember
- Use
sort_values()for column-based sorting andsort_index()when sorting by row labels. .rank()allows flexible tie-breaking strategies.duplicated(keep=False)is your friend when investigating dirty or repeating records.loc[]= label-based,iloc[]= integer/position-based. Use both to your advantage!
Explore the Full Notebook
You’ll find more than 40 guided problems with complete solutions using the material.csv and Data.csv datasets. Every line of code is explained, and the logic is grounded in real-world engineering analysis.
What You’ll Learn
- Clean and sort large datasets programmatically
- Create intelligent filters for selecting top candidates
- Detect and manage data duplications
- Build data processing logic useful for dashboards and AI pipelines
Let’s Connect!
If you enjoyed this and want more tutorials like it, follow me:
🎥 YouTube
👩💻 GitHub
💼 LinkedIn
📱 Instagram
📘 Facebook
Thanks so much for dropping by.


