
If you’re working with machine or sensor-generated logs in CSV format, mastering text data handling with Pandas is essential. This post presents a hands-on problem set focusing on real-world challenges you may encounter when working with CSV-based sensor logs. The goal is to help you practice techniques such as parsing delimited files, token-based processing, data cleaning, transformation, grouping, and summarization — all using Python’s powerful data analysis library, pandas.
What You’ll Learn
This blog walks you through multiple applied problems that mirror industrial and manufacturing scenarios involving text-formatted sensor data. Each problem is designed to reinforce:
- Efficient CSV file reading using
pandas.read_csv() - Parsing numeric data from inconsistent strings
- Creating computed flags and conditional columns
- Grouping and summarizing data for analysis
- Replacing or cleaning status labels
- Using
crosstab()for pivot-style summaries - Handling missing values and invalid rows
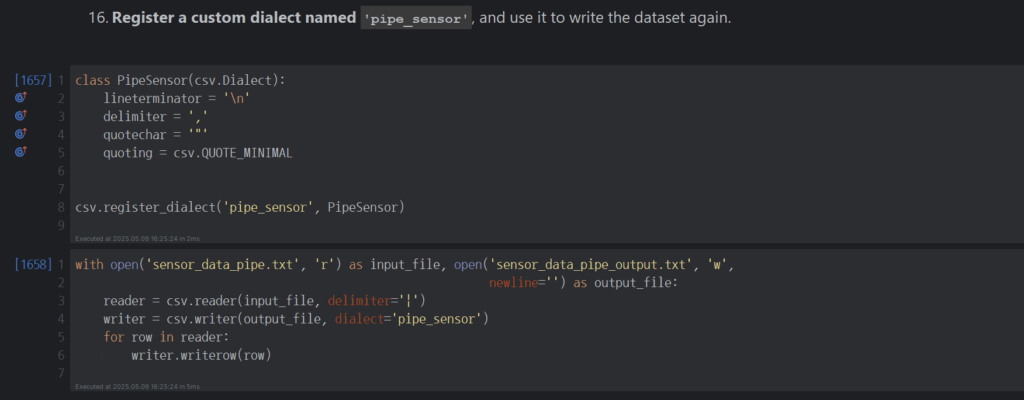
Dataset: Simulated Sensor Logs
The dataset used in this problem set represents sensor logs collected across various machine locations. Each log contains values such as:
- SensorID
- Location
- Temperature
- Humidity
- Status
These logs often include irregularities such as missing values, inconsistent formatting, or embedded symbols — making them ideal for text-based processing practice.
Sample Challenges Covered
Below are just a few examples from the problem set:
- Create a new
StatusFlagcolumn: Assign1for ‘OK’ and0for other statuses. - Group sensor data by
Locationand calculate totals and averages. - Replace status labels (e.g., ‘Critical’ ➜ ‘CR’, ‘Warning’ ➜ ‘WRN’).
- Drop invalid rows where numeric parsing fails.
- Use
pd.crosstab()to display status frequency per location. - Tokenize complex columns and extract meaningful components.
- Compute rolling statistics like 5-point moving averages.
These challenges offer a strong foundation for anyone aspiring to become proficient in data preprocessing, quality checks, and exploratory analysis.
Why This Matters
In industries like manufacturing, SCADA systems, and IoT, raw data is rarely clean. Logs may come from different sources and formats, requiring robust cleaning and transformation before analysis. This problem set helps you think like a data engineer—identifying structure in chaos, automating data preparation, and enabling downstream analytics.
Get the Code and Practice Files
You can find the full notebook and dataset on GitHub. Feel free to fork the repo and try the challenges yourself!
Final Thoughts
Whether you’re preparing for a data analytics job, working with real-world sensor systems, or refining your Python for data cleaning skills, this blog post gives you practical and contextual experience. Mastering text-based data in pandas is a must-have skill, and this exercise set is a great step toward that goal.
Let’s Connect!
If you enjoyed this and want more tutorials like it, follow me:
🎥 YouTube
👩💻 GitHub
💼 LinkedIn
📱 Instagram
📘 Facebook
Thanks so much for dropping by.


