
In today’s data-driven world, the ability to load, transform, and analyze data across multiple formats is a critical skill—especially in quality control engineering. This blog post explores how pandas, Python’s powerful data analysis library, can streamline tasks involving JSON, XML, and HTML/Web Scraping, using a simulated Coordinate Measuring Machine (CMM) dataset inspired by real-world manufacturing inspection workflows.
Note: This dataset is a simulated set and does not originate from an actual manufacturing process, but it reflects common industrial practices.
What is a Coordinate Measuring Machine (CMM)?
A CMM is a precision inspection tool used in manufacturing to evaluate the geometric dimensions and tolerances of physical parts. It verifies parameters such as:
- Flatness
- Cylindricity
- Perpendicularity
- Position tolerance
- And more…
These inspections are essential for ensuring components conform to design specs and industry standards, especially in high-precision fields like automotive and printer manufacturing.
As someone with over 10 years of experience as a QA/QC Engineer, I’ve routinely worked with CMMs in industries like automotive and consumer electronics. CMM data plays a crucial role in decision-making for process control, defect identification, and capability studies. This hands-on simulation mirrors the kinds of analysis I performed throughout my career.
About the Simulated Dataset
This dataset simulates CMM measurements from three machines (CMM A, CMM B, CMM C) operating across two shifts. It includes geometric tolerances collected from components like:
- Cylinder
- Shaft
- Cover Plate
- Disc
- Bracket
- Bushing
Dataset Fields
| Field | Description |
|---|---|
| Date | Inspection date |
| Shift | Shift 1 or Shift 2 |
| Machine ID | CMM machine used |
| Component Type | Type of part inspected |
| Flatness, Cylindricity… | Geometric tolerance measures (µm) |
| Pass/Fail | Inspection result |
This structured format is replicated in JSON, XML, and HTML-scraped tables for demonstration.
Why Use JSON, XML, and HTML?
JSON (JavaScript Object Notation)
JSON is commonly used in modern APIs and data exchange. Its structure is lightweight and easy to load using:
df = pd.read_json('path/to/file.json')
Pandas allows you to instantly convert JSON records to DataFrames, simplifying analysis across platforms like REST APIs or IoT monitoring systems.
XML (eXtensible Markup Language)
XML is still prevalent in legacy systems, ERP software, and manufacturing databases. Though more verbose, it handles hierarchical data effectively. With xml.etree.ElementTree or lxml, and a few lines of code, you can parse XML into pandas-compatible formats:
import xml.etree.ElementTree as ET
tree = ET.parse('file.xml')
root = tree.getroot()
You can then extract each <Measurement> node and load it into a DataFrame.
HTML/Web Scraping
Some critical tolerancing standards are not available in datasets—but are available on websites. For example:
- Geometric dimensioning and tolerancing (GD&T) symbols
- ISO shaft and hole tolerances
Using tools like requests, BeautifulSoup, and pandas.read_html(), you can pull tabular data from a webpage and cross-validate it with CMM measurements:
import requests
from bs4 import BeautifulSoup
soup = BeautifulSoup(requests.get(url).content, 'html.parser')
tables = pd.read_html(str(soup))
This enables logic-based comparisons between scraped tolerances and actual measurements—flagging failures, validating dimensions, and even automating inspection reports.
Why This Matters in QA/QC
Web-scraped and structured reference data—combined with real inspection records—enhances:
- Root cause analysis
- Tolerance stack-up evaluation
- Machine or shift-based performance reviews
- Failure trend detection
You’re not just collecting data—you’re deriving insights that drive decision-making and product improvement.
Pandas Makes It Effortless
Pandas allows seamless conversion between formats:
| Format | Function to Use |
|---|---|
| JSON | pd.read_json(), to_json() |
| XML | ElementTree, to_xml() |
| HTML | pd.read_html() |
| CSV | pd.read_csv(), to_csv() |
It also supports resampling, grouping, pivoting, filtering, and visualization, enabling complete QC workflows directly in Python.
Sample Insights You Can Generate
- Pass/Fail Trends by Machine or Shift
- Tolerance Drifts Over Time
- Spec Violations via Web-Scraped Limits
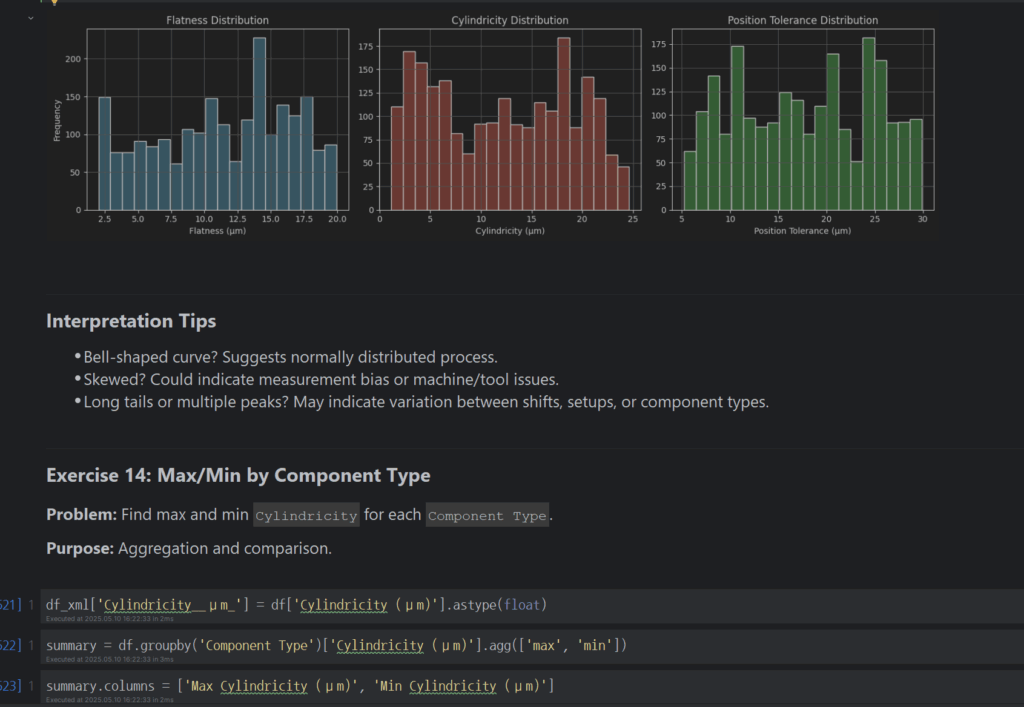
- Histogram Distributions of Flatness or Cylindricity
- Anomalies in Position Tolerance
Whether you’re an engineer, data analyst, or quality professional, this exercise set helps bridge real-world inspection with data science tools.
Get the Code and Practice Files
You can find the full notebook and dataset on GitHub. Feel free to fork the repo and try the challenges yourself!
Conclusion
As a former QA/QC Engineer, I’ve seen firsthand how effective data tools like pandas can empower quality teams. By working through these exercises using simulated CMM data, you not only improve your Python and data handling skills—but also gain insight into real-life inspection workflows and engineering analysis.
Let’s Connect!
If you enjoyed this and want more tutorials like it, follow me:
🎥 YouTube
👩💻 GitHub
💼 LinkedIn
📱 Instagram
📘 Facebook
Thanks so much for dropping by.


